|
Zom-B
Guest
|
 |
« Reply #15 on: November 17, 2009, 01:32:04 PM » |
|
|
|
|
|
|
 Logged
Logged
|
|
|
|
ker2x
Fractal Molossus

Posts: 795

|
|
« Reply #16 on: March 07, 2010, 10:05:33 AM » |
|
if you disassemble code, you'll see that x87 (FPU) is still heavily used  Also, you can do 64 bits aritmetic using SSE. SSE registers are 128bits, using ADDPD or ADDPS (just an exemple) you can add 4x32bits (ADDPS) or 2x64bits (ADDPD) packed scalar. The compiler can vectorize some obvious operation, but sometimes it's usefull to do assembly or use intresics (which is just ASM with a C syntax) I'm learning fortran, the optimization made by the fortran compilers are much more aggressive and smarter than any C compiler i ever tested, and can do much more auto-vectorization and auto-parallelisation (yes, multithreading without a single additional instruction, impressive) |
|
|
|
|
Logged
|
|
|
|
|
johandebock
|
|
« Reply #17 on: March 08, 2010, 01:39:19 PM » |
|
Nice link.
I'm investigating the usefullness of assembly optimized code for my multi-threaded Buddhabrot renderer.
I'm still looking for an easy setup to work with assembly code. Ideally as simple as changing the assembly code generated by a compiler and using that file to create the executable.
|
|
|
|
|
Logged
|
|
|
|
ker2x
Fractal Molossus
Posts: 795
|
|
« Reply #18 on: March 08, 2010, 06:04:23 PM » |
|
when i'm planning to write asm, i first write the application in purebasic, which generate a nicely commented asm file (FASM), i patch it, and i tell purebasic to recompile my patched fasm code into an standalone application. it also support inline asm. If you're already coding you app in C/C++ i suggest to use all the SSE* intresic i use http://siyobik.info/index.php?module=x86 and http://softpixel.com/~cwright/programming/simd/mmx.php as a quick reference for asm instruction. (and of course intel documentation for the complete reference) |
|
|
|
|
Logged
|
|
|
|
|
Duncan C
|
|
« Reply #19 on: March 08, 2010, 06:13:46 PM » |
|
precision actually IS the DEAL for fractal calculation  it is all about precision, with floating point you can achieve zoom levels of a factor 100.000 which is quite nice, but on zoom factors like <Quoted Image Removed> you can wonder about the decimal length calculatable nhowadays fractal programs implement own floating point algorithms to achieve that high precision   Indeed. With 32-bit floating point one can only reach depths of 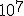 . With 64-bit double-precision, this increases to 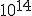 . When you want to go even deeper, most software switches over to arbitrary precision or bigint algorithms, which are SLOW AS HELL. In my own deep-zoom programs, I made an implementation of 128-bit double-double-precision emulation (not to be confused with 128-bit quad-precision), and now I can reach zooms of up to 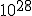 with reasonable speed. I would say it is about 6 times slower than normal double-precision math, but it is still a lot faster than arbitrary-precision as in Ultra Fractal. One can also implement 160-bit double-extended-precision, 256-bit quad-double-precision, or even higher orders of double-precision extensions, but the math involved gets exponentially more complex. If anyone wants my library (in Java), just give me a sign and I'll put it up somewhere. It contains all the usual arithmetic, polynomial, root, power, logarithmic and unary functions (not in the complex plane). I also have templates of how to convert these into complex numbers, including the trigonometric and hyperbolic functions. Indeed, double double math would be interesting. |
|
|
|
|
Logged
|
Regards,
Duncan C
|
|
|
|
Duncan C
|
|
« Reply #20 on: March 08, 2010, 06:17:36 PM » |
|
In my own deep-zoom programs, I made an implementation of 128-bit double-double-precision emulation (not to be confused with 128-bit quad-precision), and now I can reach zooms of up to <Quoted Image Removed> with reasonable speed. I would say it is about 6 times slower than normal double-precision math, but it is still a lot faster than arbitrary-precision as in Ultra Fractal.
One can also implement 160-bit double-extended-precision, 256-bit quad-double-precision, or even higher orders of double-precision extensions, but the math involved gets exponentially more complex.
If anyone wants my library (in Java), just give me a sign and I'll put it up somewhere.
Yes please, though I may not use it immediately, I would like to convert it to Objective C (and maybe C++). David, You're a fellow Mac developer? I didn't realize that. Did you know that XCODE includes native support for "long double" (128 bit quad). Based on limited benchmarking, it only appears to be about 1/2 as fast as double (64 bit) floating point. I would expect it to be 1/4 as fast. Duncan C |
|
|
|
|
Logged
|
Regards,
Duncan C
|
|
|
hobold
Fractal Bachius
Posts: 573
|
|
« Reply #21 on: March 08, 2010, 08:16:44 PM » |
|
If you want fastest possible speed, then you are probably better off not using ObjectiveC. The object model and the method binding of this language was never meant to be used for computational workloads. ObjC does have its strengths, but low overhead is not one of them.
C++ does have a different object model that was specifically designed for low overhead. But even here the overhead is greater than zero in some relevant cases.
If at all possible, try to stick with plain old C for lowest level of compute intensive stuff. That way, you can later use it from either C++ or ObjC.
|
|
|
|
|
Logged
|
|
|
|
|
Duncan C
|
|
« Reply #22 on: March 08, 2010, 08:51:43 PM » |
|
If you want fastest possible speed, then you are probably better off not using ObjectiveC. The object model and the method binding of this language was never meant to be used for computational workloads. ObjC does have its strengths, but low overhead is not one of them.
C++ does have a different object model that was specifically designed for low overhead. But even here the overhead is greater than zero in some relevant cases.
If at all possible, try to stick with plain old C for lowest level of compute intensive stuff. That way, you can later use it from either C++ or ObjC.
I would put that more generally. If you want the fastest compute code, use vanilla C, period. Don't use ANY object-oriented language. However, that does not mean your app can't be written in an object-oriented language. You just have to draw a circle around your compute-intensive code, and write that in carefully optimized vanilla C. I am willing to put my app, FractalWorks, against any other Mandelbrot/Julia renderer out there for raw speed. It is highly optimized; It takes symmetry into account, it uses boundary following to identify contiguous "blobs" of pixels with the same iteration value, and only computes the perimeter of those blobs; it is multi-threaded and will spawn an arbitrary number of worker threads based on the number of cores available, etc. It uses Objective C for most of the above, but the inner code to iterate a strip of pixels is pure C. I question whether or not it's still practical to create hand-written assembler for such things. These days there is a great deal going on that isn't well documented or understood: Predictive execution, pipelining, multi-level caches, parallel execution paths, etc, etc. Modern optimizing compilers are very sophisticated, and create very well tuned code. If you really, really know what you are doing, and spend months writing the eqivalent of a few hundred lines of C code, you may be able to beat well written C by a small margin, but I think the days of doubling the performance of a block of code in assembler are basically over. |
|
|
|
« Last Edit: March 08, 2010, 09:42:23 PM by Duncan C, Reason: typo »
|
Logged
|
Regards,
Duncan C
|
|
|
|
David Makin
|
|
« Reply #23 on: March 08, 2010, 09:05:08 PM » |
|
In my own deep-zoom programs, I made an implementation of 128-bit double-double-precision emulation (not to be confused with 128-bit quad-precision), and now I can reach zooms of up to <Quoted Image Removed> with reasonable speed. I would say it is about 6 times slower than normal double-precision math, but it is still a lot faster than arbitrary-precision as in Ultra Fractal.
One can also implement 160-bit double-extended-precision, 256-bit quad-double-precision, or even higher orders of double-precision extensions, but the math involved gets exponentially more complex.
If anyone wants my library (in Java), just give me a sign and I'll put it up somewhere.
iPhone/iTouch/iPad at the moment but Mac as soon as I get a Mac at home rather than just at work. Yes please, though I may not use it immediately, I would like to convert it to Objective C (and maybe C++). David, You're a fellow Mac developer? I didn't realize that. Did you know that XCODE includes native support for "long double" (128 bit quad). Based on limited benchmarking, it only appears to be about 1/2 as fast as double (64 bit) floating point. I would expect it to be 1/4 as fast. Duncan C iPhone/iTouch/iPad at the moment, Mac as soon as I get a Mac at home as well as at work |
|
|
|
|
Logged
|
|
|
|
|
David Makin
|
|
« Reply #24 on: March 08, 2010, 09:18:46 PM » |
|
If you want fastest possible speed, then you are probably better off not using ObjectiveC. The object model and the method binding of this language was never meant to be used for computational workloads. ObjC does have its strengths, but low overhead is not one of them.
C++ does have a different object model that was specifically designed for low overhead. But even here the overhead is greater than zero in some relevant cases.
If at all possible, try to stick with plain old C for lowest level of compute intensive stuff. That way, you can later use it from either C++ or ObjC.
I would put that more generally. If you want the fastest compute code, use vanilla C, period. Don't use ANY object-oriented language. However, that does not mean your app can't be written in an object-oriented language. You just have to draw a circle around your compute-intensive code, and write that in carefully optimized vanilla C. I am willing to put my app, FractalWorks, against any other Mandelbrot/Julia renderer out there for raw speed. It is highly optimized; It takes symmetry into account, it uses boundary following to identify contiguous "blobs" of pixels with the same iteration value, and only computes the perimeter of those blobs; it is multi-threaded and will span an arbitrary number of worker threads based on the number of cores available, etc. It uses Objective C for most of the above, but the inner code to iterate a strip of pixels is pure C. I question whether or not it's still practical to create hand-written assembler for such things. These days there is a great deal going on that isn't well documented or understood: Predictive execution, pipelining, multi-level caches, parallel execution paths, etc, etc. Modern optimizing compilers are very sophisticated, and create very well tuned code. If you really, really know what you are doing, and spend months writing the eqivalent of a few hundred lines of C code, you may be able to beat well written C by a small margin, but I think the days of doubling the performance of a block of code in assembler are basically over. When I said convert it to Objective C and C++ I just meant so it could be used from GUI controllers in those formats, knowing me I'd probably attempt conversion of the number crunching to assembler - I still prefer programming in assembler to higher languages and do not trust any higher level compiler to produce optimum run-time code especially where the FPU is concerned (unless of course I wrote the compiler myself). Having said that, the last ASM code I did was for the ARM and not the x86 (a blitter library done for the older WM devices). |
|
|
|
|
Logged
|
|
|
|
|
Duncan C
|
|
« Reply #25 on: March 09, 2010, 01:55:50 AM » |
|
iPhone/iTouch/iPad at the moment, Mac as soon as I get a Mac at home as well as at work Really? Small world. My company is also focusing on iPhone/iPod touch/iPad development. We're a self-funded startup, so work and home are the same place at the moment... Do you have a background in Objective C/Cocoa development? Duncan |
|
|
|
|
Logged
|
Regards,
Duncan C
|
|
|
|
David Makin
|
|
« Reply #26 on: March 09, 2010, 03:09:38 AM » |
|
iPhone/iTouch/iPad at the moment, Mac as soon as I get a Mac at home as well as at work Really? Small world. My company is also focusing on iPhone/iPod touch/iPad development. We're a self-funded startup, so work and home are the same place at the moment... Do you have a background in Objective C/Cocoa development? Duncan Not really, I started from scratch with respect to Apple based development for the iPhone and (although 47) I've only been coding in C/C++ since around 2002 when I was forced to do so to develop for the Windows PPC and Smartphone - prior to that all my coding was ASM e.g. MMFrac (PC/32-bit DOS), Crystal Dragon (Amiga), Tower of Souls (Amiga/PC/mobile devices), the 3D Pets series (PC) and a number of unused/unreleased items such as a GameAPI for Windows Mobile and a CPU/FPU based 3D engine (first Pentiums) that I unfortunately just finished as it was made redundant by the first true 3D graphics cards |
|
|
|
|
Logged
|
|
|
|
|
David Makin
|
|
« Reply #27 on: March 09, 2010, 03:11:56 AM » |
|
iPhone/iTouch/iPad at the moment, Mac as soon as I get a Mac at home as well as at work Really? Small world. My company is also focusing on iPhone/iPod touch/iPad development. We're a self-funded startup, so work and home are the same place at the moment... Do you have a background in Objective C/Cocoa development? Duncan Not really, I started from scratch with respect to Apple based development for the iPhone and (although 47) I've only been coding in C/C++ since around 2002 when I was forced to do so to develop for the Windows PPC and Smartphone - prior to that all my coding was ASM e.g. MMFrac (PC/32-bit DOS), Crystal Dragon (Amiga), Tower of Souls (Amiga/PC/mobile devices), the 3D Pets series (PC) and a number of unused/unreleased items such as a GameAPI for Windows Mobile and a CPU/FPU based 3D engine (first Pentiums) that I unfortunately just finished as it was made redundant by the first true 3D graphics cards I should add that for me work (at Parys Technografx) is just Steve Parys' front room |
|
|
|
|
Logged
|
|
|
|
|
utak3r
|
|
« Reply #28 on: March 09, 2010, 08:43:51 PM » |
|
As of the subject of this topic... if you're using only CPU power - it pays off well. In Apophysis I have almost every formula written both in Delphi and asm. The rendertime differences are really worth of it.
Of course - it's unportable, but still...
|
|
|
|
|
Logged
|
|
|
|
|
Duncan C
|
|
« Reply #29 on: March 10, 2010, 12:59:53 PM » |
|
iPhone/iTouch/iPad at the moment, Mac as soon as I get a Mac at home as well as at work Really? Small world. My company is also focusing on iPhone/iPod touch/iPad development. We're a self-funded startup, so work and home are the same place at the moment... Do you have a background in Objective C/Cocoa development? Duncan Not really, I started from scratch with respect to Apple based development for the iPhone and (although 47) I've only been coding in C/C++ since around 2002 when I was forced to do so to develop for the Windows PPC and Smartphone - prior to that all my coding was ASM e.g. MMFrac (PC/32-bit DOS), Crystal Dragon (Amiga), Tower of Souls (Amiga/PC/mobile devices), the 3D Pets series (PC) and a number of unused/unreleased items such as a GameAPI for Windows Mobile and a CPU/FPU based 3D engine (first Pentiums) that I unfortunately just finished as it was made redundant by the first true 3D graphics cards I've written quite a bit of assembler in my day as well. In the early days, it was 6502, for the Apple II. Then 8086/8088, for the early IBM PC. (I wrote a word processor for the IBM PC in assembler, for a now-defunct company called Muse Software.) Then 68000 family. This is when I wrote hand-tuned floating point code, for Macs with an FPU. I haven't written much assembler in years however. It takes too long, and is too hard to maintain. I also question the payback, given the sophistication of modern processors and compilers. I would like to see a comparison of well written C vs well-written assembler for fractal calculation. Regards, Duncan C |
|
|
|
|
Logged
|
Regards,
Duncan C
|
|
|
|










