The really interesting thing is, it's a macro, and it can be called simply with "(:= z (+ (** z 2) c))" and it will spit out a loop that calculates the M-set.
Not only that, it takes two parameters, bitsprecision and a number-system object. If bitsprecision is high enough, it will spit out a loop that uses bignums instead of IEEE doubles. Orthogonally, the number-system object is defined in terms of a list of unit-symbols, a unit multiplication table, and a collection of functions for reciprocal and transcendental functions. Passing different number systems to the macro generates different versions of the loop. I could generate a loop that iterated only real numbers (say, for generating a bifurcation diagram), and I've also implemented the number system objects for quaternions and what Fractint calls hypercomplex numbers (except no transcendentals yet; I have to implement those for bignum reals and for non-reals.)
Basically, it does symbolic algebra to convert the input assignment-like expressions and number-system info into more assignment-like expressions, representing the same math but decomposed into the individual real-number components. So two input-expressions become four with complex arithmetic and eight with quaternions. These are then subjected to algebraic simplification, which can extract common factors, apply the distributive rule, collect like terms, and similarly -- this step turns a (+ (* z-r z-i) (* z-i z-r)) into a (* 2 z-r z-i) in the case of the standard Mandelbrot fractal, for example. Yes, it does detect if terms are the same even if products or sums are rearranged. And since this step is applied after reduction to real-number arithmetic, it doesn't matter that quaternions are noncommutative; by the time simplify sees quat expressions, they're groups of four real expressions rather than quat expressions, and real multiplication
is commutative.
The upshot: by implementing a fair bit of a symbolic-algebra package and one lousy macro I have ANY non-transcendental map, to ANY precision, in real, complex, quaternion, or hypercomplex arithmetic.
I don't have to write the inner loops for everything separately. The computer does it for me.

Best of all, the loops are
fast. The IEEE double loop it spits out for plain old complex quadratic Mandelbrot is 40% faster than Ultra Fractal's inner loop. The bignum loop is 7 times slower than UF's at 22 decimals, for now, but I plan to fix that. Plus this thing will get speed enhancements elsewhere.
For starters, the system can in fact compile a loop on the fly for each specific image, or even each layer, with parameter values baked in as constants. So if I want to generate a Julia set image for
c =
i, the loop it generates will be short one add because the real part of
c is zero and it can just generate a loop that has
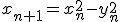
. (Ultra Fractal can do this too, but only in the context of its formula interpreter. My macro does it and puts out
native code.)
Furthermore, some stuff you can't do in UF without multiple layers that duplicate one another's calculations, this software will do with a single calculation of each pixel and smarter handling of the resulting data. I also plan to have faster bailout tests: instead of looking for convergence to a possibly-expensive-to-test shape, it will run a high speed loop that tests for exit of a square or circular area, then iterate a lower-speed loop until it hits the target shape. So for most iterations, say 999700+ out of 1 million for a deep point, it will not be using the expensive bailout test.
The Lisp being used is Clojure, which runs on a JVM. This means this stuff is portable to every system that has a JVM, fast on every system that has a good JITting JVM, and interoperates nicely with Java. (The current bignum implementation, which sucks, uses java.math.BigDecimal. I will probably adapt the BSD-licensed JScience LargeInteger code to make a custom one that's faster, particularly by using Karatsuba multiplication when it gets really REALLY big. With that, it will probably beat Fractint(!) at hundreds of decimals.)
The Java interoperation means programs built on this core have ready access to GUI, PNG encode/decode, other image formats, the network, and so forth.
Last but not least, Clojure's eval is available at deployment time, so the formula parser is nearly fully written: the user will be able to just type "z^4 - z^2 + c" and the computer will grind away, compile a function to JVM byte-codes to iterate that really really fast, and off it goes, with the JIT putting the finishing touch on it.
Did I mention that the loop-generating code does common subexpression elimination? And that all of this has been tested and found to work? 100 million iterations in under 700msec on my E5200; UF takes about 1 second to do that many iterations on one core on the standard Mandelbrot zoomed into the cardioid and with guessing and periodicity checking turned off.
That, by the way, is what's next: adding periodicity logic to the emitted loops, controlled by a parameter, and a slightly smarter bailout. Right now it generates a circular/spherical bailout zone, though it also does common subexpression elimination between the iteration steps and computing the squared modulus. It needs to be smarter: detecting if it's cheaper to test a sphere or a square and choosing accordingly what code to emit. For the normal M-set, a sphere is cheap because
x2 and
y2 are needed anyway. Add an add and a compare and you've got your bailout test, versus four compares for a square bailout. On the other hand, if there were no
x2 or
y2 already needed elsewhere, the circular bailout test becomes two multiplies, an add, and a compare instead of four compares. Since adds, subtracts, and compares tend to be comparable in expense and multiplies tend to be more expensive than any of those, four compares is cheaper in this instance. A multiply, an add, and a compare might be cheaper than four compares though, so it might be worthwhile to use a sphere if it's a complex number and one of the squares is needed. For higher dimensions
d, there are 2
d compares needed for a hypercube,
d multiplies,
d minus one adds, and a compare needed for a sphere, so many of the squares would need to be already needed for this to be a winner. How many? Probably hardware-dependent. I'll have to experiment.
Further down the line: add distance estimator capability. I've determined that to support most of the common colorings, and many of my own custom ones, you just need the last iterate and the number of iterations. The major exceptions:
- Distance estimator, Lyapunov exponent, and similar require the derivative. Add another boolean flag to the parameter list and a bit more symbolic algebra and we can emit loops that compute the derivative.
- Assorted things, like traps, that use the whole orbit.
Clojure supports a concept of lazy sequences, so we can generate a lazy sequence of iterates that, under the hood, runs a fast iteration loop to spit out 64,000 at a time (or however many), then trickles these out to the sequence's consumer, then generates some more. Alternatively, the caller can just feed the existing macro a few extra expressions to compute to accumulate a weighted sum or whatever.
Heck, I don't even need to add a flag to compute a derivative/Jacobian; I can just create symbolic algebra code to compute
how to compute the derivative/Jacobian and then append those to the list of expressions fed to the macro. The output loop will compute them all and the derivative will be right after the last iterate in the array of output values. And the macro will do common subexpression elimination between all of these various calculations, so if
xy appears in a lot of places, the output code will assign it to a temporary and then use that repeatedly.
Oh, and did I mention I've implemented what I've implemented so far in
four days? In a week at that rate I'll have derivatives, Jacobians, and what-have-you. (Yes, it already will iterate functions of more than one variable, such as the Henon map.) In a month at that rate, a working demo that renders PNG images and breaks all kinds of speed records.
It's shocking that nobody much else is apparently developing fractal software in Lisp, given what it's capable of.











