|
cbuchner1
|
 |
« Reply #45 on: July 18, 2010, 10:34:58 PM » |
|
I run much more thread than available core (usually 1 million per frame, much more if i have a low (<1000) maxiter).
When a tread complete, a new thread pick a new pair of random number (according to its unique global_id) from the 2 randomBuffer.
The 2 randomBuffers are filled by another kernel. So i never need to transfer randoms from host to device.
It may take longer that you expect for a new thread to start up: The scheduling granularity of the nVidia hardware is in so-called "warps" of 32 threads. So while one thread within a warp is still active but the other threads have terminated, these threads will sit idle until the last working thread finishes. A similar inefficiency exists at the block level in nVidia's Compute Capability 1.x hardware: New blocks are only fed to the GPU by the driver when about half of all active blocks have terminated (as an example you have 14 multiprocessors on a nVidia 8800GT, so 7 blocks must have terminated before new blocks are fed to the hardware). On Fermi architecture (Compute Capability >= 2.0) this behavior has been improved (block scheduling was moved from the driver into the hardware, which they named "Gigathread engine") This should also apply to OpenCL in much the same way, even though the naming of threads, warps and blocks may be slightly different (a "block" becomes a "work group" in OpenCL) I still can't get my GTX 460 to work under Linux or Windows XP Prof. (seems my mainboard BIOS doesn't like this card!), so I am starting to do Buddhabrots in CUDA on my laptop's 9600M graphics card (32 shaders). I will be trying to utilize shared memory as much as possible to prevent the scattered writes to global memory. |
|
|
|
« Last Edit: July 18, 2010, 10:56:39 PM by cbuchner1 »
|
 Logged
Logged
|
|
|
|
ker2x
Fractal Molossus

Posts: 795

|
|
« Reply #46 on: July 18, 2010, 11:16:03 PM » |
|
in progress ... 175k sample/s at 100k max iteration  A deeper zoom on the left "bulb" of the above pic at 10k iterations . (took a few hours to render)  |
|
|
|
« Last Edit: July 19, 2010, 10:11:17 AM by ker2x »
|
Logged
|
|
|
|
|
cbuchner1
|
|
« Reply #47 on: July 18, 2010, 11:46:31 PM » |
|
in progress ... 175k sample/s at 100k max iteration
How do you define sample? Does a sample represent a scattered write to the accumulation buffer, or is it a complex starting point for an orbit? Is this number for your 8800 card or for the Ion2 ? |
|
|
|
|
Logged
|
|
|
|
ker2x
Fractal Molossus
Posts: 795
|
|
« Reply #48 on: July 18, 2010, 11:55:42 PM » |
|
in progress ... 175k sample/s at 100k max iteration
How do you define sample? Does a sample represent a scattered write to the accumulation buffer, or is it a complex starting point for an orbit? Is this number for your 8800 card or for the Ion2 ? numbers for the 8800GTX. Technically, a "sample" is a thread. so it is what you call "a complex starting point for an orbit". |
|
|
|
|
Logged
|
|
|
|
|
|
ker2x
Fractal Molossus
Posts: 795
|
|
« Reply #50 on: July 19, 2010, 11:42:34 PM » |
|
Okay, a nicer one. around 10mn of computation on my Laptop. Sorry about the ugly jpg compression, it's a screenshot, i need to implement a way to print the real result (in HDR if possible) with a lossless compression. Source code available here : http://github.com/ker2x/WinBuddhaOpenCL |
|
|
|
« Last Edit: July 19, 2010, 11:46:34 PM by ker2x »
|
Logged
|
|
|
|
|
cbuchner1
|
|
« Reply #51 on: July 20, 2010, 12:26:01 AM » |
|
Nice, I also got some first B/W images today with CUDA. Using my tiled rendering method in shared memory seems to slow things down currently.
I also tried two buddhabrot variations:
1) I multiplied the contribution of each orbit with its length.
2) I divided the contribution of each orbit by its total length.
One could combine the original buddhabrot with these two variations in the three R,G,B channels to result in a much different colorization.
I could also imagine using some nonlinear functions, such as gaussians centered at different locations on the "number of iterations" axis, that emphasize different orbit lengths for the R,G, and B color channels.
|
|
|
|
« Last Edit: July 20, 2010, 12:36:52 AM by cbuchner1 »
|
Logged
|
|
|
|
ker2x
Fractal Molossus
Posts: 795
|
|
« Reply #52 on: July 20, 2010, 12:42:10 AM » |
|
Nice, I also got some first B/W images today with CUDA
I also tried two buddhabrot variations:
1) I multiplied the contribution of each orbit with its length.
2) I divided the contribution of each orbit with its total length.
Yay \o/ I'd love to see your progress and results. I'm planning to try cuda too. Feel free to post your dev diary here (with code if opensource (hopefully)). |
|
|
|
|
Logged
|
|
|
|
|
cbuchner1
|
|
« Reply #53 on: July 20, 2010, 04:45:56 PM » |
|
Selectively plotting only the contributions for orbits of length <= 10 iterations and in the second picture those of length 10 to 20.
Or how about this third image: Selectively plotting only the 10th step from ANY orbit below the cutoff (256 iterations).
Combining all of this opens some interesting new ways of coloring. Creating animations by generating image sequences with parameter sweeps of the above restrictions is also possible. One could also compute "smooth" orbit lengths (instead of integer ones), which would allow for more gradual parameter sweeps.
So as you see I am currently more interested in exporing variations of the original Buddha- and Nebulabrots. The original horse has been beaten to death already, I am try to cross-breed some donkeys and zebras now.
I have a last one for you: Plotting iteration 5 of all orbits of length 100 and greater (but below the cutoff of 256)
|
|
|
« Last Edit: July 20, 2010, 05:45:10 PM by cbuchner1 »
|
Logged
|
|
|
|
ker2x
Fractal Molossus
Posts: 795
|
|
« Reply #54 on: July 20, 2010, 06:58:12 PM » |
|
I have a last one for you: Plotting iteration 5 of all orbits of length 100 and greater (but below the cutoff of 256)
Very nice, and interesting  My code should be able to do the same thing. i'm going to try |
|
|
|
|
Logged
|
|
|
|
ker2x
Fractal Molossus
Posts: 795
|
|
« Reply #55 on: July 20, 2010, 07:02:54 PM » |
|
A new colorfull buddha : 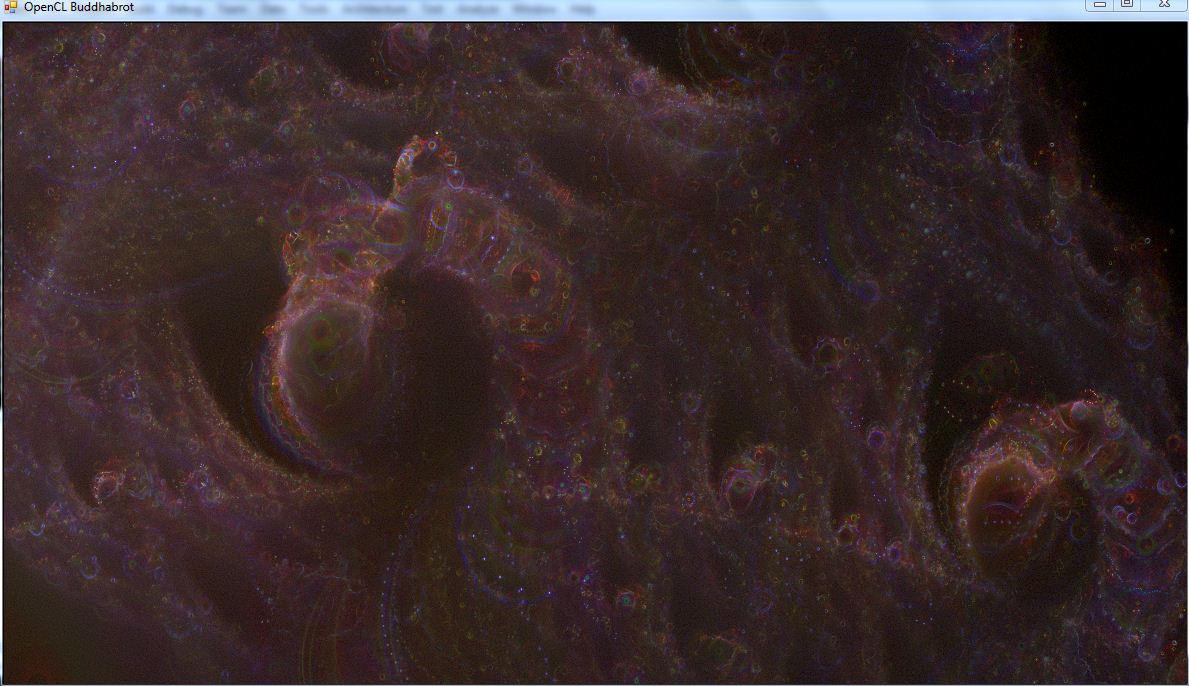 Red : 20k -> 60k iterations Green : 60k -> 100k iterations Blue : 100k -> 200k iterations |
|
|
|
|
Logged
|
|
|
|
|
kram1032
|
|
« Reply #56 on: July 20, 2010, 10:15:14 PM » |
|
those are some nice variations  |
|
|
|
|
Logged
|
|
|
|
|
cbuchner1
|
|
« Reply #57 on: July 20, 2010, 11:38:11 PM » |
|
There are more things I want to try tomorrow.
I could try to restrict my random generator to a specific region in the complex plane. So the set of starting points for iterating will be from a small, confined region - so this will render only a small part of the orbits contributing to the "complete" buddhabrot.
I could then move this source region over the complex plane and watch the resulting buddhabrot change its shape. Also I could pick three different source regions and generate three distinct color channels from.
But first I need a way to create proper HDR exposures, save frames, combine three grayscale frames to a color image and assemble an animation from this source data. Plenty of "boring" routine jobs before I get the exciting animations.
|
|
|
|
« Last Edit: July 20, 2010, 11:59:21 PM by cbuchner1 »
|
Logged
|
|
|
|
ker2x
Fractal Molossus
Posts: 795
|
|
« Reply #58 on: July 21, 2010, 08:55:05 AM » |
|
i still have a problem with coloring, so i added just a pinch of contrast with irfanview :  the same one with heavy-duty postprocessing (reveal interesting details) :  same position, differents iteration :  |
|
|
|
« Last Edit: July 21, 2010, 01:10:31 PM by ker2x »
|
Logged
|
|
|
|
|
cbuchner1
|
|
« Reply #59 on: July 21, 2010, 02:27:55 PM » |
|
so this will render only a small part of the orbits contributing to the "complete" buddhabrot.
No longer the average buddhabrot : -all orbits start within axis-aligned ellipse bounded by (-2.0, 2.0), i*(-1.0, 0.0). -only plotting orbits length 100 or more (but below cutoff 256) -weighting each orbit with a factor proportional to ln(orbit length) I have started looking into the Metropolis-Hastings algorithm to speed up zooming. I have also split off my random number generation from the actual rendering code and I think I can fully integrate this algorithm into the random generator. EDIT: yup, works. |
|
|
« Last Edit: July 22, 2010, 09:48:23 PM by cbuchner1 »
|
Logged
|
|
|
|
|









