|
Pauldelbrot
|
 |
« Reply #45 on: June 22, 2016, 01:44:07 PM » |
|
Nanoscope's current threshold is actually for the squared magnitude to be 1/1000 or less; that corresponds to an unsquared magnitude ratio of approximately 1/32.
I am interested to know what the glitch detection logic is in the other major perturbation renderers, KF and Mandel Machine.
|
|
|
|
|
 Logged
Logged
|
|
|
|
|
Kalles Fraktaler
|
|
« Reply #46 on: June 23, 2016, 09:05:59 AM » |
|
Nanoscope's current threshold is actually for the squared magnitude to be 1/1000 or less; that corresponds to an unsquared magnitude ratio of approximately 1/32.
I am interested to know what the glitch detection logic is in the other major perturbation renderers, KF and Mandel Machine.
The code of KF is available on my site, even though it is not updated for a while, the glitch methods are the same. KF use 0.0000001, which corresponds to an unsquared magnitude of 0.0003162... Further I use a buffer of integers to represent the iteration values for each pixel, and a buffer of float to represent the smooth value for each pixel, with values between 0 to 1. If a glitch is detected, the smooth value is set to 2 for that pixel. Next reference is used to re-calculating all pixels indicated as glitch with smooth value 2. By doing so, one could add the new references randomly in these glitch indicated pixels, even though it may be ineffective. But it is probably faster than trying to use high precision to do any advanced decision on where to put the next reference. |
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus

Posts: 652
|
|
« Reply #47 on: June 23, 2016, 01:09:39 PM » |
|
Nanoscope's current threshold is actually for the squared magnitude to be 1/1000 or less well, i had read your original post to say 1e-3, so thats what ive rolled with all this time, 1e-6 for the squared magnitude, and it seems fine. By doing so, one could add the new references randomly in these glitch indicated pixels, even though it may be ineffective. is that to say this is what you do? originally when i was trying to figure out what to do, i decided to pick the "deepest" glitched point to use for the next reference, simply the point with the greatest distance to the nearest non-glitched point. ive been meaning to take a look at this again, what a more perfect approach might be. i think claude has discussed some more straightforward, more proper approach. i forget if it was based on which point glitched first, or based on the derivative, or something else. have to dig through his posts again sometime. i know he also mentioned applying newton's method to further refine the reference point once youve chosen it. these things are all well and good when you are calculating the derivative, though it would be nice to also have as proper a method as possible for use with a non-DE mode. |
|
|
|
|
Logged
|
|
|
|
|
Kalles Fraktaler
|
|
« Reply #48 on: June 23, 2016, 07:16:37 PM » |
|
is that to say this is what you do? originally when i was trying to figure out what to do, i decided to pick the "deepest" glitched point to use for the next reference, simply the point with the greatest distance to the nearest non-glitched point. ive been meaning to take a look at this again, what a more perfect approach might be. i think claude has discussed some more straightforward, more proper approach. i forget if it was based on which point glitched first, or based on the derivative, or something else. have to dig through his posts again sometime. i know he also mentioned applying newton's method to further refine the reference point once youve chosen it. these things are all well and good when you are calculating the derivative, though it would be nice to also have as proper a method as possible for use with a non-DE mode.
No, I am trying to use some kind of flood fill function to idenfity the largest separated glitch area, and then try to and the next reference in the center of it. But the flood fill is not measuring too large areas, since some large AA would make it extremely slow. So not random, but not much more either. I think newton's method would be best, but not practially when going deep. |
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #49 on: June 23, 2016, 08:28:17 PM » |
|
ah, so our methods are basically the same i think. i am using an OpenCV distance function for it, and i think my opencv is set to use the GPU, so it is pretty fast and does not incur a noticeable slowdown. i suspect if it ran it on the cpu it might be noticeably slower. still, it would be nice to eliminate this entirely if you can select as good or better reference points by simply using the iteration and/or derivative data.
|
|
|
|
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563

|
|
« Reply #50 on: June 23, 2016, 09:26:51 PM » |
|
well, i had read your original post to say 1e-3, so thats what ive rolled with all this time, 1e-6 for the squared magnitude, and it seems fine. I use this value too, 1e-6 for squared magnitude, 1e-3 for magnitude. i think claude has discussed some more straightforward, more proper approach. i forget if it was based on which point glitched first, or based on the derivative, or something else. have to dig through his posts again sometime. i know he also mentioned applying newton's method to further refine the reference point once youve chosen it. these things are all well and good when you are calculating the derivative, though it would be nice to also have as proper a method as possible for use with a non-DE mode.
In mandelbrot-perturbator[1] I use a tree structure for recursively solving glitches. At the iteration P when a glitch occurs, I find the pixel with the minimum |Z+deltaZ| value, whose C is near the minibrot of period P whose influence is causing the glitch. At the minibrot's nucleus the |Z+deltaZ| would be 0, because of the periodicity, so using the derivative calculated anyway for DE, you can do one step of Newton's method very cheaply (no need to do any more iterations) to get a better new reference (said minibrot of period P). Then rebase all the pixels that glitched (at the same iteration number with the same parent reference) to the new reference, no need to restart from the beginning, because of periodicity: the new deltaZ is just Z+deltaZ, the new deltaC is a translation by the difference of the old and new reference (be sure to use the correct sign). [1] https://code.mathr.co.uk/mandelbrot-perturbator - very messy pre-alpha code, not really ready for public consumption yet (in particular the dependencies on my other projects are a bit fiddly to get set up build-wise) |
|
|
|
|
Logged
|
|
|
|
|
Pauldelbrot
|
|
« Reply #51 on: June 24, 2016, 01:46:22 AM » |
|
No, I am trying to use some kind of flood fill function to idenfity the largest separated glitch area, and then try to and the next reference in the center of it.
But the flood fill is not measuring too large areas, since some large AA would make it extremely slow.
So not random, but not much more either.
I think newton's method would be best, but not practially when going deep.
Since KF seems to work fine with 1e-7 sensitivity instead of the much more picky 1e-3, I'm trialling that value in Nanoscope. Nanoscope uses the same method now to pick references, instead of the original fairly complex contracting-net scheme. The flood fill recently had to be adapted to use a hash set instead of a stack to avoid excessive memory consumption on large glitches -- it was blowing up on a glitch that took up about 40% of a 30-megapixel image until I made that change. Pixels would get added to the stack, then added again from a different direction and visited, leaving one instance still on the stack, which wouldn't be revisited again for a very long time. Checking that it was visited and not recursing was fast, but the accumulation of dead pixels on the stack got into the tens of millions for that giant glitch. I wasn't sanguine about a queue being much better, but a set discards duplicate elements. The set only grew to in the tens of thousands, but was very slow because of poor locality of memory accesses to the image bitmap. Changing from a hash set to a tree set sorted on coordinates made it very fast and cheap, only around 9000 at its largest size finding the middle of the same glitch, because it restored locality of successive memory accesses and further reduced the set's size and complexity (it would have grown haphazardly and contains weird holes with a hash set, versus returning to the same scanning behavior of the stack with the tree set). Of course, averaging the coordinates of the glitch member pixels to find the barycenter is only the first step. If the glitch is ring shaped (as one is in one of Dinkydau's test locations) the barycenter won't be glitched! So if the selected center pixel is non-glitched, it walks a straight line from the initial glitched pixel to the barycenter, one pixel width at a time (using FP coordinates instead of integers for this bit), until it hits a nonglitched pixel and then returns the pixel that is halfway along this line segment. So, with a ring it's going to pick a point halfway from the ring's outer rim to its inner rim, for example. |
|
|
|
|
Logged
|
|
|
|
|
Pauldelbrot
|
|
« Reply #52 on: June 24, 2016, 03:42:28 AM » |
|
The code of KF is available on my site, even though it is not updated for a while, the glitch methods are the same.
KF use 0.0000001  ?? In my testing, this does not catch the glitch in Dinkydau's "Flake" image. OTOH, KF 2.10 renders the "Flake" image correctly. The image is shallow enough that differences in the approaches taken to handling large exponents (over e308) shouldn't enter into it. Is KF using anything unusual, beyond ordinary double-precision FP, when calculating the "Flake" image? |
|
|
|
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563
|
|
« Reply #53 on: June 24, 2016, 03:51:16 AM » |
|
?? could possibly be down to differences in reference point selection? I don't know.. |
|
|
|
|
Logged
|
|
|
|
|
Kalles Fraktaler
|
|
« Reply #54 on: June 27, 2016, 01:18:36 PM » |
|
?? In my testing, this does not catch the glitch in Dinkydau's "Flake" image. OTOH, KF 2.10 renders the "Flake" image correctly. The image is shallow enough that differences in the approaches taken to handling large exponents (over e308) shouldn't enter into it. Is KF using anything unusual, beyond ordinary double-precision FP, when calculating the "Flake" image? No, there is no magic, and the code (somewhat outdated but this part has not been changed for long) is available on http://www.chillheimer.de/kallesfraktaler/for (i = 0; i<nMaxIter && !m_bStop; i++){
xin = (xr + xi).Square() - sr - si + m_iref;
xrn = sr - si + m_rref;
xr = xrn;
xi = xin;
sr = xr.Square();
si = xi.Square();
m_nRDone++;
m_db_dxr[i] = xr.ToDouble();
m_db_dxi[i] = xi.ToDouble();
abs_val = (g_real*m_db_dxr[i] * m_db_dxr[i] + g_imag*m_db_dxi[i] * m_db_dxi[i]);
m_db_z[i] = abs_val*0.0000001;
if (abs_val >= terminate){
if (nMaxIter == m_nMaxIter){
nMaxIter = i + 3;
if (nMaxIter>m_nMaxIter)
nMaxIter = m_nMaxIter;
m_nGlitchIter = nMaxIter;
}
}
}
|
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #55 on: September 16, 2016, 08:35:42 PM » |
|
i forget if this has been discussed before, but going over these parts of my code again got me to thinking, is there a variation on paul's glitch test that would not involve taking the magnitude? since this requires you to compute squared values, it seems that this should halve the precision range that the test will actually be good for. ie, 1e-200 * 1e-200 = 1e-400, so here for instance you have underflowed if using double. so then either the test is no good or you compensate by using a bigger slower type.
|
|
|
|
« Last Edit: September 16, 2016, 08:43:57 PM by quaz0r »
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563
|
|
« Reply #56 on: September 16, 2016, 09:37:51 PM » |
|
i forget if this has been discussed before, but going over these parts of my code again got me to thinking, is there a variation on paul's glitch test that would not involve taking the magnitude? since this requires you to compute squared values, it seems that this should halve the precision range that the test will actually be good for. ie, 1e-200 * 1e-200 = 1e-400, so here for instance you have underflowed if using double. so then either the test is no good or you compensate by using a bigger slower type.
Good point, this underflow might cause things to be detected as glitches when they are fine (if using <=) or not detected as glitches at all (if using <). There are ways of avoiding under/overflow when computng magnitude, but they don't apply if you use magnitude-squared to avoid the square root computation. |
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #57 on: September 16, 2016, 09:49:07 PM » |
|
yeah, i think we've all been using magnitude squared to avoid the square root. the precision issue though seems to invalidate this approach, whereas some kind of shortcut to a non-squared magnitude sounds like just the ticket. noting also that for those who put a hard boundary on where they increase precision, ie if you jump from double to your next biggest type at a hard boundary of a magnification of 1e308 or whatever, you are likely shielding yourself from the precision issue given the fact that the series approximation will usually be initializing 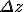 to values substantially larger than 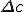 . but this does not mean the precision issue doesnt exist. looking at the perturbation code again, it looks like not only the |z| computations have this issue, but also the iteration itself. * There is one more thing to check: the previously mentioned bigger downward jumps in log|deltai| are caused by sudden drops in the magnitude of the reference orbit (|Zm|). So we have to be sure that minValue = |deltaN| * minm>N|Zm| > 10-308 here botond kosa was describing his method of determining when it is safe to scale down the precision of the perturbation iterations. i think perhaps this sort of forward-looking approach is really what is needed to guarantee a proper outcome? i think this still leaves the question regarding the computation of the magnitudes for the glitch detection however, or would this cover that too? thinking more about this, i guess the z values wont usually be too small unless you are zooming in very far on the real or imaginary axis, so maybe the magnitudes could only ever underflow in locations like a deep zoom on the needle. |
|
|
|
« Last Edit: September 16, 2016, 11:09:47 PM by quaz0r »
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #58 on: October 26, 2016, 01:52:47 AM » |
|
In mandelbrot-perturbator I use a tree structure for recursively solving glitches. At the iteration P when a glitch occurs, I find the pixel with the minimum |Z+deltaZ| value, whose C is near the minibrot of period P whose influence is causing the glitch. At the minibrot's nucleus the |Z+deltaZ| would be 0, because of the periodicity, so using the derivative calculated anyway for DE, you can do one step of Newton's method very cheaply (no need to do any more iterations) to get a better new reference (said minibrot of period P). Then rebase all the pixels that glitched (at the same iteration number with the same parent reference) to the new reference, no need to restart from the beginning, because of periodicity: the new deltaZ is just Z+deltaZ, the new deltaC is a translation by the difference of the old and new reference (be sure to use the correct sign).
i was going to see about implementing this, though im not sure if i totally get it (im not really familiar yet with how the period stuff works and such): do we know for sure that one iteration of newtons method will always land you in the center of the desired minibrot ? do we know for sure that the period of that minibrot is P, or could P be some multiple of the actual period or vice versa ? if P is definitely the period, can we then say that our new reference can simply consist of P iterations, which we could then index as iter%P ? what is the new Z value to start the new reference ? or are we starting it at the beginning ? |
|
|
|
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563
|
|
« Reply #59 on: October 26, 2016, 06:27:34 PM » |
|
i was going to see about implementing this, though im not sure if i totally get it (im not really familiar yet with how the period stuff works and such):
do we know for sure that one iteration of newtons method will always land you in the center of the desired minibrot ? No, but it should give a few more bits of accuracy compared to the estimate of "nearest pixel". do we know for sure that the period of that minibrot is P, or could P be some multiple of the actual period or vice versa ? It could be a multiple of the true period I suppose. It's worth investigating, to see if it occurs or even matters in practice. Note that if you create a new reference at its true period, it won't be created again (glitch detection test will fail as refZ will be 0 at multiples of the period). if P is definitely the period, can we then say that our new reference can simply consist of P iterations, which we could then index as iter%P ? I suppose so! Rounding errors might cause problems, though. - chances are that you don't use enough bits of precision to stop the secondary reference escaping eventually.. what is the new Z value to start the new reference ? or are we starting it at the beginning ? The new delta-Z value is the old reference-Z+delta-Z value (which is near 0 by the glitch detection test), and iteration continues from where it is. No starting from scratch. |
|
|
|
|
Logged
|
|
|
|
|










