claude
Fractal Bachius

Posts: 563

|
 |
« on: April 10, 2016, 09:07:43 PM » |
|
I benchmarked some implementations of complex number squaring: https://mathr.co.uk/blog/2016-04-10_complex_squaring.htmlKalles Fraktaler's way (3 real squares) is faster than Karatsuba (2 real multiplies) only for MPFR precision between 3000-100000. The naive method (2 squares, 1 multiplcation) is never the best. |
|
|
|
|
 Logged
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #1 on: April 10, 2016, 09:40:13 PM » |
|
this sounds like a fundamental performance thing i was mostly unaware of  whenever i square something i just do x*x ... but there is a magic square function that implements some kind of math hax to make it faster? how about for hardware floating point, is there a magic function for that also or is that just x*x ? it looks like the c++ wrapper im using for mpfr calls mpfr_sqr for its sqr function. you mention mpc_sqr in your article. is it the same thing? another thing i was wondering about was multiplying by 2. i was noticing my code doing x+x and thinking to myself, hmm, there ought to be a mpfr function for multiplying by 2 by just adjusting the exponent or something? |
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #2 on: April 10, 2016, 09:52:30 PM » |
|
oh i just realized you were talking about complex squaring  but the fact that there is a mpfr_sqr function still makes me wonder if there is still some special implementation for squaring real numbers? ok looking at your article again i realized why my mind immediately got drawn from complex squaring to squaring real numbers... you list the individual operations of squaring and multiplying real numbers separately so it does seem like we are considering them different.. |
|
|
|
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563
|
|
« Reply #3 on: April 10, 2016, 10:02:24 PM » |
|
for hardware floating point I use x*x too, but for arbitrary precision a special squaring function can be a fair bit faster than a regular multiply. arbitrary precision libraries use a vector of limbs, each small enough that hardware operations can be used for them. here's a multiplication with 3 limbs (considered as polynomial in the base): (d + ex + fx^2) = ad + (ae + bd) x + (be + af + cd) x^2 + O(x^3)) now for squaring, 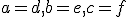 so the right hand side can be simplified: ^2 = a^2 + 2ab x + (b^2 + 2ac) x^2 + O(x^3)) here  are typically 64bit words (sometimes 32bit, it depends), and this doesn't take into account the carrying/normalization that needs doing to get it all to fit together properly but you can already see that this multiply takes 6 word-multiplies and 3 word-adds while the squaring takes only 4 word-multiplies, 1 word-add and 2 shifts in actualilty this grade-school algorithm probably isn't used by MPFR and other high-quality arbitrary precision libraries except at low precisions, there are asymptotically faster ones like Karatsuba and Toom-Cook and even FFT-based methods for when you need to multiply huge numbers. MPC is a C-wrapper for complex numbers around MPFR for real numbers. mpc_sqr squares a complex number, mpfr_sqr squares a real number. mpfr_mul_2si multiplies by a power of two very cheaply |
|
|
|
|
Logged
|
|
|
|
|
Kalles Fraktaler
|
|
« Reply #4 on: April 10, 2016, 11:08:48 PM » |
|
claude, so you did all calculations in mpr right?
Does that consider the optimizations one can do when calculating Mandelbrot?
That is, when using an array of hardware datatypes for arbitrary precision of say length 10, multiplying would involve 10x10=100 operations, but you can ignore half of them sinne the output precision is the same as the imput. And when squaring, you can ignore 75% of them since half of the 50% is the same?
I hope you understand what I mean. This is well described by the creator of fractal extreme (Bruce), I can find it for you if you want?
I assume the gain of only squaring is even bigger considering this optimization...
|
|
|
|
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563
|
|
« Reply #5 on: April 10, 2016, 11:51:32 PM » |
|
Yes I used MPFR for all arbitrary precision calculation in the benchmark. MPFR has lots of optimisations built in, like the ones you mention. My benchmark only compares some different usages of MPFR to do complex squaring (MPFR is only for real numbers). I could have been clearer in my post, the reason I counted squares and multiplications separately is because of the MPFR-provided optimized functions (where square(x) is cheaper than multiply(x,x)). My reply to quaz0r was about real numbers, you explained it much more concisely, thanks!
|
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #6 on: April 11, 2016, 01:28:06 AM » |
|
to be clear then is what karl mentioned actually a mandelbrot-specific optimization or just a general optimization of arbitrary precision implementation? if the latter then im sure mpfr implements it, if the former i imagine it does not. ive seen people mention it on previous occasions as a mandelbrot-specific optimization, but it sounds like that is not the case?
|
|
|
|
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563
|
|
« Reply #7 on: April 11, 2016, 01:34:12 AM » |
|
None of this is Mandelbrot-specific, MPFR provides mpfr_sqr and mpfr_mul, and the MPC library for complex numbers over MPFR provides mpc_sqr (which uses (x+y)(x-y) for the real part) and mpc_mul too.
|
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #8 on: April 11, 2016, 02:15:10 AM » |
|
your benchmarks are pretty impressive for karatsuba. im looking at my reference calculations and it looks like i had implemented it as calculating a^2 and b^2 at full precision, saving (a^2 + b^2) * 1e-6 for each iteration to use for paul's glitch detection, and then recycling the a^2 and b^2 for the (a^2 - b^2) of the next iteration of z. i guess maybe i could instead do the karatsuba thing, and get away with calculating a^2 and b^2 at lower precision for the glitch detection? and it would be faster?
|
|
|
|
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563
|
|
« Reply #9 on: April 11, 2016, 02:18:43 AM » |
|
something to try I guess, try it and report back (I'm guessing grabbing a and b to double precision then calculating a^2+b^2 should work fine for glitch detection).
|
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #10 on: April 11, 2016, 07:08:14 AM » |
|
so is karatsuba better than naive for hardware floating point as well as arbitrary precision? in days gone by i think addition was faster than multiplication but i think they are supposed to be equal now. here the difference comes down to 2 multiplies 1 add versus 2 adds 1 multiply, so i guess it should be a push?
|
|
|
|
|
Logged
|
|
|
|
claude
Fractal Bachius
Posts: 563
|
|
« Reply #11 on: April 11, 2016, 07:31:20 AM » |
|
the naive way might be faster because the compiler could use SIMD to do vec3(x, y, x) * vec3(x, y, y) = vec3(x^2, y^2, xy) in one instruction. but this is just a guess, disassembling a small snippet would tell for sure.
|
|
|
|
|
Logged
|
|
|
|
quaz0r
Fractal Molossus
Posts: 652
|
|
« Reply #12 on: April 11, 2016, 07:55:28 AM » |
|
hmm well personally im already using explicit vectorization, iterating N points in parallel for vector size N, so probably still a push for me i guess. on a side note i think compiler auto-vectorization is basically utter crap / practically worthless as yet. they can auto-vectorize the simplest of loops and inject some misc vector code like what you are talking about (though probably not even that fancy) and even then i think people have taken a look at the code that is actually being generated and it is similar performance or sometimes worse than if the compiler doesnt generate vector instructions and such. *shrug* |
|
|
|
|
Logged
|
|
|
|
|
Kalles Fraktaler
|
|
« Reply #13 on: April 11, 2016, 09:43:51 AM » |
|
to be clear then is what karl mentioned actually a mandelbrot-specific optimization or just a general optimization of arbitrary precision implementation? if the latter then im sure mpfr implements it, if the former i imagine it does not. ive seen people mention it on previous occasions as a mandelbrot-specific optimization, but it sounds like that is not the case?
I don't know about mpr but I do know that other arbitrary precision libraries do not implement the Mandelbrot optimization. If you want to make a 100% correct multiplication of say 10 digits, you must do all the 100 operations and produce 20 digits, because the least significant digit can theoretically turn all 9s into 10s and change the most significant digit. So in those libraries, even if you specify 10 digits as precision, it will internally use 20 for a correct multiplication. But when calculating Mandelbrot such small values can be ignored, and that even in apparently non-approximation programs like fractal extreme. But the gain is 50%, and for squaring, 75%! Just saying... |
|
|
|
« Last Edit: April 11, 2016, 10:33:42 AM by Kalles Fraktaler, Reason: typos... »
|
Logged
|
|
|
|
|









