|
Sockratease
|
 |
« Reply #105 on: July 12, 2015, 03:24:08 PM » |
|
Has anybody else noticed a general trend for the AI to put doggies on brightly colored areas and buggies on darker colored areas?
I begin to see how this thing thinks! Going to test this theory...
How better to test this idea than with a black and white photo of Bettie Page?  Pretty sure that is Terms Of Service compliant. I can be blind to such things, so if not... I am confident that it will be removed with no hard feelings  But it does support my theory:  I never thought of Bettie Page as a dog, but ... She's a very pretty dog! WOOF! But notice the dress has more of the snakes and centipedes while the brighter areas have more doggies and birds. It's not an absolute rule, but it seems to favor one over the other in terms of distribution based on color as a guide. |
|
|
|
« Last Edit: July 12, 2015, 03:33:44 PM by Sockratease, Reason: Speelinf Eroorz »
|
 Logged
Logged
|
Life is complex - It has real and imaginary components. The All New Fractal Forums is now in Public Beta Testing! Visit FractalForums.org and check it out! |
|
|
|
kram1032
|
|
« Reply #106 on: July 12, 2015, 03:47:20 PM » |
|
Well, presumably to some extent it uses color information.
For instance, in that twitch bot that just keeps on dreaming indefinitely, there are some clear trends: Bananas tend to make the image more yellowy, strawberries more reddish, volcanoes tend to cause a ton of darkness - almost blackness - along with a few bright red splotches (so there is a clear emergent behavior of rocky bits and lava) while bubbles, which often contain some bright reflection, will overally tend to lighten up the image...
So clearly, color information is present in the resulting vectors.
It's definitely not an absolute though: I once saw bubbles that remained rather dark for the entire minute of run-time and it was one of the most beautiful bubble runs there was.
|
|
|
|
|
Logged
|
|
|
|
|
Sockratease
|
|
« Reply #107 on: July 12, 2015, 04:34:14 PM » |
|
I was just thinking in terms of AI Psychology. Bright = Happy = Puppy Dogs  Dark = Scary = Buggy Bugs  Again, not a strict rule, but a general theme. Meanwhile, Interesting results from a Z Buffer image of a Cow made for use in MB3D!   But note the doggy in the nose? Black area. Expected bugs there... Guess it just likes dogs! |
|
|
|
|
Logged
|
Life is complex - It has real and imaginary components. The All New Fractal Forums is now in Public Beta Testing! Visit FractalForums.org and check it out! |
|
|
|
Syntopia
|
|
« Reply #108 on: July 12, 2015, 05:23:38 PM » |
|
Yeah, the guided stuff will not create new objects which are not part of the 1000 item training set. Instead of guiding using a image, it would be easier if you could specify the categories directly.
Here is one guided by insects:
|
|
|
|
Logged
|
|
|
|
|
Syntopia
|
|
« Reply #109 on: July 12, 2015, 05:24:12 PM » |
|
And another one guided by beer:
|
|
|
|
Logged
|
|
|
|
tit_toinou
Iterator

Posts: 192
|
|
« Reply #110 on: July 12, 2015, 05:25:08 PM » |
|
This definitely needs a new section there is too much potential in this... Just like someone said earlier in the topic, we should try to feed neural network with fractal patterns (the easiest would be to take the images from the Mandelbrot Safari from Pauldebrot in fractalforums !) and apply the same technique to images from the real world. That would be much more interesting ; I'm tired of seeing theses dogs & birds faces emerging all the time  I would prefer fractals patterns to emerge. |
|
|
|
|
Logged
|
|
|
|
|
Chillheimer
|
|
« Reply #111 on: July 12, 2015, 06:51:11 PM » |
|
This definitely needs a new section there is too much potential in this...
I second that. What do you think Christian? Now that I finally can do HiRes dreaming up to 2560*1440 I'm confronted with the following problem: It seems like the shapes that are dreamed (like dogfaces, buildings..) have a fixed pixel size. This means if I did a picture in 500pix width and it had e.g. 2 dogfaces in there (say 200 pixels in diameter), when I redo the same image to achieve higher resolution, I get a totally different output. I get 2*5=10 dogfaces. still 200 pixels in diameter, but they look much smaller in the total picture.. --maybe a picture is easier. up is the one dreamed in 1024, lower is dreamed in 2048 and then downscaled to 1024. see how the temples are half the size? How can I prevent that? Any idea, Syntopia perhaps? |
|
|
|
Logged
|
--- Fractals - add some Chaos to your life and put the world in order. ---
|
|
|
|
kram1032
|
|
« Reply #112 on: July 12, 2015, 07:16:54 PM » |
|
What would that new category be? AI-guided or -transformed art? That, then, would include:
<a href="https://www.youtube.com/v/buXqNqBFd6E&rel=1&fs=1&hd=1" target="_blank">https://www.youtube.com/v/buXqNqBFd6E&rel=1&fs=1&hd=1</a>or http://picbreeder.org/among other things. It really likes dogs simply because its training set proportionally contained a lot more dogs than anything else because so many of its categories are separate breeds of dogs. If it was trained more evenly amongst different categories - either by providing multiple categories for more specific variations of things other than dogs, or by reducing "dog" to a single categoriy - you'd end up with much more varied pics, I expect. |
|
|
|
|
Logged
|
|
|
|
|
Syntopia
|
|
« Reply #113 on: July 12, 2015, 07:34:26 PM » |
|
Now that I finally can do HiRes dreaming up to 2560*1440 I'm confronted with the following problem:
It seems like the shapes that are dreamed (like dogfaces, buildings..) have a fixed pixel size.
The Google script applies the reverse transformation at different scales (which they call 'octaves'). Per default they use 4 different scales, each scaled by a factor 1.4x. Try increasing the number of octaves: you will still get the small structures, but some larger structure might survive from the smaller scales. The parameters are called: octave_n=4, octave_scale=1.4 in the script. It really likes dogs simply because its training set proportionally contained a lot more dogs than anything else because so many of its categories are separate breeds of dogs. If it was trained more evenly amongst different categories - either by providing multiple categories for more specific variations of things other than dogs, or by reducing "dog" to a single categoriy - you'd end up with much more varied pics, I expect.
I count something like 120 dogs out of the 1000 categories. Since they are adjacent in the feature vector (entry 152 to 269), I imagine it should be possible to minimize the influence of these categories somehow. But the problem is the way the Google script works, is by transferring features from some intermediate layer from the guide (e.g. 'inception_4c/output') - and here the dimensions do not correspond nicely to the 1000 categories. I'm pretty sure it can be done - if I recall correctly one of the earlier online scripts allowed you to tweet categories? |
|
|
|
|
Logged
|
|
|
|
|
3dickulus
|
|
« Reply #114 on: July 12, 2015, 09:08:18 PM » |
|
5cents  I have 6G system mem and a 2G nVidia card, rendering 2880x3840 image requires 3.1G system mem (includes running X11 desktop) Using cnn-vis https://github.com/jcjohnson/cnn-vis with cuDNN in cnn-vis the gfx card mem is used for calculating, not holding image data, the image data goes to a png file, the --batch-size option controls how much ram/threads is used on the GPU, I get this output no matter what the image dimensions are when --batch-size=128 ... I0712 11:20:44.759096 8298 net.cpp:213] Network initialization done.
I0712 11:20:44.759105 8298 net.cpp:214] Memory required for data: 800160768 I can push it past 128 but at 128 and less seems to perform better using hybridCNN_iter_700000_upgraded.caffemodel |
|
|
|
|
Logged
|
|
|
|
|
cKleinhuis
|
|
« Reply #115 on: July 12, 2015, 09:24:49 PM » |
|
What would that new category be? AI-guided or -transformed art? That, then, would include:
so, i would say the new category should just be "AI" because in my eyes its not the art that strikes out here, its the applied neuronal network stuff in action which is going to be used for far more different stuff, so, perhaps a new main board "Neural Networks - AI" with subsections "Art", "and whatever comes to our minds to group it " |
|
|
|
|
Logged
|
---
divide and conquer - iterate and rule - chaos is No random!
|
|
|
|
cKleinhuis
|
|
« Reply #116 on: July 12, 2015, 09:31:39 PM » |
|
so, and art forms we have here would be "music creation/recognition" "image creation/recognition" "talk/turing tests"
|
|
|
|
|
Logged
|
---
divide and conquer - iterate and rule - chaos is No random!
|
|
|
|
kram1032
|
|
« Reply #117 on: July 12, 2015, 09:36:29 PM » |
|
If you actually want to make a new category out of this (I'm honestly not sure if the current amount of content warrants this, although surely the fairly new future will bring a lot more of this), this thread and the other two should probably be moved to there, then.
|
|
|
|
|
Logged
|
|
|
|
|
3dickulus
|
|
« Reply #118 on: July 13, 2015, 02:59:34 AM » |
|
a new main board "Neural Networks - AI" with subsections "Art", "and whatever comes to our minds to group it "
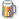 @Chillheimer I ran into the same thing, these two pics are reduced from 3840x2880, one is at 10 iterations the other is at 100 |
|
|
« Last Edit: July 13, 2015, 03:21:41 AM by 3dickulus, Reason: pics for Chilli »
|
Logged
|
|
|
|
|
|
|









