|
Kuemmel
Guest
|
 |
« on: November 15, 2009, 03:41:20 PM » |
|
Hi guys, I just recently found this forum. Over some time now, as being interested in assembler coding and fractals, I developed my own little Mandelbrot benchmark, to see how the new CPU architectures can be used efficiently, what leads to surprising results and speed ups. You can find my code here (all based on double precision SSE2/FPU variants): http://www.mikusite.de/pages/x86.htmLooking around here I just wondered what would be fun and more or less usefull to code in assembler next. So in other ways, what would be really in the need of a speed-up, something like the new 3D-algorithms, or is the lack of speed there more the rendering and not the iterations ? |
|
|
|
|
 Logged
Logged
|
|
|
|
|
David Makin
|
|
« Reply #1 on: November 15, 2009, 05:35:54 PM » |
|
Hi guys, I just recently found this forum. Over some time now, as being interested in assembler coding and fractals, I developed my own little Mandelbrot benchmark, to see how the new CPU architectures can be used efficiently, what leads to surprising results and speed ups. You can find my code here (all based on double precision SSE2/FPU variants): http://www.mikusite.de/pages/x86.htmLooking around here I just wondered what would be fun and more or less usefull to code in assembler next. So in other ways, what would be really in the need of a speed-up, something like the new 3D-algorithms, or is the lack of speed there more the rendering and not the iterations ? Rendering the 3D fractals has 2 main routes to optimisation - improving the ray-stepping algorithm so that fewer steps are required to find the solid boundary and improving the efficiency of the main iteration loop (as you say). The first can only really be improved if there's a breakthrough in the maths theory but the second can certainly be improved by using optimised assembly code. Personally I am no longer interested in assembly code until such time that I can program for a Mac instead of Windows. |
|
|
|
|
Logged
|
|
|
|
|
cKleinhuis
|
|
« Reply #2 on: November 15, 2009, 06:28:48 PM » |
|
in my opinion pure single core assembler code is no more needed nowadays, today development focusses on parallel graphics card (gpu) hardware, gpu optimized algorithms for those areas are still under development, but many different approaches exists for those purposes already  |
|
|
|
|
Logged
|
---
divide and conquer - iterate and rule - chaos is No random!
|
|
|
|
David Makin
|
|
« Reply #3 on: November 15, 2009, 09:37:44 PM » |
|
in my opinion pure single core assembler code is no more needed nowadays, today development focusses on parallel graphics card (gpu) hardware, gpu optimized algorithms for those areas are still under development, but many different approaches exists for those purposes already I disagree if the "pure single core assembler" is written so it will multi-thread on say a dual Quadcore Nehalem system  |
|
|
|
|
Logged
|
|
|
|
|
lycium
|
|
« Reply #4 on: November 15, 2009, 10:28:18 PM » |
|
yup, writing assembly is basically a waste of time; will you write it for 64bit computers, or will you write it for 32bit computers? how about both?
if you use intel's sse intrinsic instructions, the compiler does the grunt work of combinatorial instruction scheduling and register allocation.
|
|
|
|
|
Logged
|
|
|
|
|
David Makin
|
|
« Reply #5 on: November 15, 2009, 10:54:23 PM » |
|
yup, writing assembly is basically a waste of time; will you write it for 64bit computers, or will you write it for 32bit computers? how about both?
if you use intel's sse intrinsic instructions, the compiler does the grunt work of combinatorial instruction scheduling and register allocation.
SSE ? I didn't think that was accurate enough, guess it's a while since I read a processor manual |
|
|
|
|
Logged
|
|
|
|
|
lycium
|
|
« Reply #6 on: November 15, 2009, 11:00:25 PM » |
|
x87 is dead since years now; actually in 64bit (AMD64 architecture) it's not supported at all, everything is done via (scalar) sse, and that's a great thing since that horrible horrible stack-based register architecture needed to die a long time ago!
|
|
|
|
|
Logged
|
|
|
|
|
David Makin
|
|
« Reply #7 on: November 15, 2009, 11:08:11 PM » |
|
yup, writing assembly is basically a waste of time; will you write it for 64bit computers, or will you write it for 32bit computers? how about both?
if you use intel's sse intrinsic instructions, the compiler does the grunt work of combinatorial instruction scheduling and register allocation.
SSE ? I didn't think that was accurate enough, guess it's a while since I read a processor manual I meant last time I looked SSE was just float not double |
|
|
|
|
Logged
|
|
|
|
|
Kuemmel
Guest
|
|
« Reply #8 on: November 16, 2009, 12:00:56 AM » |
|
Rendering the 3D fractals has 2 main routes to optimisation - improving the ray-stepping algorithm so that fewer steps are required to find the solid boundary and improving the efficiency of the main iteration loop (as you say). The first can only really be improved if there's a breakthrough in the maths theory but the second can certainly be improved by using optimised assembly code.
Personally I am no longer interested in assembly code until such time that I can program for a Mac instead of Windows.
Hi David, okay, I see, so the iterations seems to be interesting, can you send me any C-code for the iteration loop of a nice 3D fractal formula so that I can use it as a base and play with that ? Regarding the others, of course it's may be sometimes a waste of time, but I still think it's kind of factor 2 or even more faster than some C-code. I already support multi core up to 32 cores in my benchmark. So one could say on an i7 quad core with hyper threading it's 8 cores * SSE2 (2 double's) makes about a parallelism of 16. Isn't it still the problem of GPU's that they only support single precision or some kind of not precise double thing ? For fun I also coded my benchmark with x87 FPU (a real pain in the ass with the stack), a lot slower on modern CPU's compared to SSE2 of course...I just wondered if the extended precision could be of some use for fractals, but I guess it's not a big deal. For the moment I stick to 32bit coding, as 64bit OS seems not to be that wide spread. Depending on the algorithm 64bit mainly helps with the double amount of registers (16 SSE2 double precision registers), what can be quite helpful, as it means kind of less access to memory needed. |
|
|
|
|
Logged
|
|
|
|
|
cKleinhuis
|
|
« Reply #9 on: November 16, 2009, 12:38:43 AM » |
|
precision actually IS the DEAL for fractal calculation it is all about precision, with floating point you can achieve zoom levels of a factor 100.000 which is quite nice, but on zoom factors like 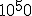 you can wonder about the decimal length calculatable nhowadays fractal programs implement own floating point algorithms to achieve that high precision   |
|
|
|
|
Logged
|
---
divide and conquer - iterate and rule - chaos is No random!
|
|
|
|
David Makin
|
|
« Reply #10 on: November 16, 2009, 12:56:24 AM » |
|
To me for Fine Art quality images then double precision is a minimum but for animations float is OK, so at the moment I'd only be interested in GPU for animation - or for preview renders while setting up. The new GPU thingy from Intel that Thomas keeps mentioning sounds more interesting |
|
|
|
|
Logged
|
|
|
|
|
lycium
|
|
« Reply #11 on: November 16, 2009, 01:01:49 AM » |
|
i don't "keep" mentioning it, do i?  anyway, you guys can stick to your cpu asm coding if it makes you happy |
|
|
|
|
Logged
|
|
|
|
|
Zom-B
Guest
|
|
« Reply #12 on: November 16, 2009, 02:22:05 PM » |
|
precision actually IS the DEAL for fractal calculation it is all about precision, with floating point you can achieve zoom levels of a factor 100.000 which is quite nice, but on zoom factors like <Quoted Image Removed> you can wonder about the decimal length calculatable nhowadays fractal programs implement own floating point algorithms to achieve that high precision Indeed. With 32-bit floating point one can only reach depths of 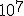 . With 64-bit double-precision, this increases to 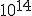 . When you want to go even deeper, most software switches over to arbitrary precision or bigint algorithms, which are SLOW AS HELL. In my own deep-zoom programs, I made an implementation of 128-bit double-double-precision emulation (not to be confused with 128-bit quad-precision), and now I can reach zooms of up to 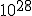 with reasonable speed. I would say it is about 6 times slower than normal double-precision math, but it is still a lot faster than arbitrary-precision as in Ultra Fractal. One can also implement 160-bit double-extended-precision, 256-bit quad-double-precision, or even higher orders of double-precision extensions, but the math involved gets exponentially more complex. If anyone wants my library (in Java), just give me a sign and I'll put it up somewhere. It contains all the usual arithmetic, polynomial, root, power, logarithmic and unary functions (not in the complex plane). I also have templates of how to convert these into complex numbers, including the trigonometric and hyperbolic functions. |
|
|
|
|
Logged
|
|
|
|
|
David Makin
|
|
« Reply #13 on: November 16, 2009, 03:04:33 PM » |
|
In my own deep-zoom programs, I made an implementation of 128-bit double-double-precision emulation (not to be confused with 128-bit quad-precision), and now I can reach zooms of up to <Quoted Image Removed> with reasonable speed. I would say it is about 6 times slower than normal double-precision math, but it is still a lot faster than arbitrary-precision as in Ultra Fractal.
One can also implement 160-bit double-extended-precision, 256-bit quad-double-precision, or even higher orders of double-precision extensions, but the math involved gets exponentially more complex.
If anyone wants my library (in Java), just give me a sign and I'll put it up somewhere.
Yes please, though I may not use it immediately, I would like to convert it to Objective C (and maybe C++). |
|
|
|
|
Logged
|
|
|
|
|
Duncan C
|
|
« Reply #14 on: November 17, 2009, 03:23:57 AM » |
|
precision actually IS the DEAL for fractal calculation it is all about precision, with floating point you can achieve zoom levels of a factor 100.000 which is quite nice, but on zoom factors like <Quoted Image Removed> you can wonder about the decimal length calculatable nhowadays fractal programs implement own floating point algorithms to achieve that high precision Indeed. With 32-bit floating point one can only reach depths of . With 64-bit double-precision, this increases to . When you want to go even deeper, most software switches over to arbitrary precision or bigint algorithms, which are SLOW AS HELL. In my own deep-zoom programs, I made an implementation of 128-bit double-double-precision emulation (not to be confused with 128-bit quad-precision), and now I can reach zooms of up to with reasonable speed. I would say it is about 6 times slower than normal double-precision math, but it is still a lot faster than arbitrary-precision as in Ultra Fractal. One can also implement 160-bit double-extended-precision, 256-bit quad-double-precision, or even higher orders of double-precision extensions, but the math involved gets exponentially more complex. If anyone wants my library (in Java), just give me a sign and I'll put it up somewhere. It contains all the usual arithmetic, polynomial, root, power, logarithmic and unary functions (not in the complex plane). I also have templates of how to convert these into complex numbers, including the trigonometric and hyperbolic functions. I'd also be interested in seeing that library. I'd have to convert it to C, but that shouldn't e that hard... Duncan |
|
|
|
|
Logged
|
Regards,
Duncan C
|
|
|
|










