|
Dinkydau
|
 |
« Reply #15 on: May 09, 2013, 06:38:00 PM » |
|
incredible results, to make the differences more clear, can you exactly render same resolutions, and then using the same colormap, e.g. 256 grayscales that repeat, and then subtract the images from eachother to show the errors ?
That would be a good idea, but I don't understand the way the gradient works in SFT. Maybe someone else can do this. As far as I can see the results are accurate. hehe, with this incredible new zoom depths will be possible   muahahar, expecting new deep zoom records soon! Looks like I wasted months of render time on that deep zoom to over 2^3000 which isn't even finished yet. Still it's a positive thing. |
|
|
|
|
 Logged
Logged
|
|
|
|
|
mrflay
|
|
« Reply #16 on: May 09, 2013, 08:30:05 PM » |
|
I'm on Windows 7 x64 version running Chrome but all I got was a blank page, then after (quite) a while Chrome crashed all my windows and I had to restart it.
Don't think I'll try again as the same thing happened to me last night when I clicked the link.
I think the high memory version seems to be causing some stability problems. I tried Chrome, and it crashed like it did for you. However the low memory version seemed to work fine on chrome in my brief test. I might change my web page to make the low memory version the default one. The extra memory is only needed for exporting very large images. |
|
|
|
|
Logged
|
|
|
|
|
mrflay
|
|
« Reply #17 on: May 09, 2013, 08:43:48 PM » |
|
The multiplication of <Quoted Image Removed> and <Quoted Image Removed> (or in general of a small number with a number of order 1) still gives a result with the same precision of <Quoted Image Removed> (mantissas are multiplicated first with full precision, then it's rounded to float precision and the exponents are added). But even if we can say that we have a high precision on the result we still cut away details from <Quoted Image Removed>, so we can only work on points that can be represented with floats.
In equation (1) 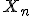 is a long arbitrary precision number. However it is multiplied by 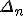 , which is a small number, so the full precision of is not needed. For example, if you want your calculation to have a precision of 100 decimal places, and is less than 1e-90, then you only need the first 10 significant figures of X_n. Note that once starts to get big, you don't need to do the calculation with as much precision, so generally you don't need to increase the precision of X_n. |
|
|
|
|
Logged
|
|
|
|
|
cKleinhuis
|
|
« Reply #18 on: May 09, 2013, 10:13:35 PM » |
|
i am going to mention this method in the upcoming news issue, it would be great if you could provide the essential algorithm, as far as i understand this can even lead to deeper zooms on a gpu with just floating points ? if for an image just one exact location would be needed this could be done on the cpu, and the rest on the gpu ?!
|
|
|
|
|
Logged
|
---
divide and conquer - iterate and rule - chaos is No random!
|
|
|
|
mrflay
|
|
« Reply #19 on: May 09, 2013, 11:49:05 PM » |
|
i am going to mention this method in the upcoming news issue, it would be great if you could provide the essential algorithm, as far as i understand this can even lead to deeper zooms on a gpu with just floating points ? if for an image just one exact location would be needed this could be done on the cpu, and the rest on the gpu ?!
That should work. The gpu code would need to access the values of X n, so they would have to be stored in a texture or something similar. Also it should be possible to get past the 1e-38 limit by scaling the A, B and C coefficients. SuperFractalThing does this to enable it to render images that have a size too small to store in a double precision number. |
|
|
|
|
Logged
|
|
|
|
brucedawson
Forums Newbie

Posts: 6
|
|
« Reply #20 on: May 10, 2013, 03:04:29 AM » |
|
[quote author=Dinkydau link=topic=15559.msg61119#msg61119 date=1368114595]
...
zoom level = 5.054594E-264, equivalent to 2^879.33 in Fractal extreme
iteration_limit = 13824
resolution = 1024×768 The results: | Software | Calculation time (m:ss) | | Fractal extreme | 2:52,400 | | SuperFractalThing | 0:11,686 |
That is a really significant decrease in render time! [/quote] That's fascinating. I don't understand why chaos theory doesn't make this fail, but I guess I'll have to give it a try. One thing to watch out for. If Java is using double precision floating point numbers then I suspect this will fail at around a magnification of 10^308 (about a thousand zooms). At around that point a double does not have the range to represent the difference between the left and right edge of the image, and some time before that a double does not have the range to represent the difference between two pixels. I hit variations on this problem a few times while working on Fractal eXtreme. This isn't an insurmountable problem -- it just means that something more complex than double will be needed. That also means that getting it working on GPUs will be trickier beyond that level. Good algorithms beat optimized code. |
|
|
|
|
Logged
|
|
|
|
|
cKleinhuis
|
|
« Reply #21 on: May 10, 2013, 03:55:58 AM » |
|
wow, surely worth a mention regarding chaos theory ... its "just" deterministic chaos, and it still is hard to predict, but this awesome encounter just moves the border a few hundred defimals farther awesome, fantastic work Mr.Flay ! |
|
|
|
|
Logged
|
---
divide and conquer - iterate and rule - chaos is No random!
|
|
|
|
mrflay
|
|
« Reply #22 on: May 12, 2013, 07:15:10 PM » |
|
That should work. The gpu code would need to access the values of Xn, so they would have to be stored in a texture or something similar. Also it should be possible to get past the 1e-38 limit by scaling the A, B and C coefficients. SuperFractalThing does this to enable it to render images that have a size too small to store in a double precision number.
Also SuperFractalThing stores the numbers 2-X n to help it accurately calculate the first iteration where |Y n|>2. However I think this is only really needed for points near -2. A dynamic gpu zoomer would be able to use the same reference point data for several frames, so the speed of calculating the X n values shouldn't be a problem. |
|
|
|
|
Logged
|
|
|
|
|
mrflay
|
|
« Reply #23 on: May 12, 2013, 07:25:23 PM » |
|
One thing to watch out for. If Java is using double precision floating point numbers then I suspect this will fail at around a magnification of 10^308 (about a thousand zooms). At around that point a double does not have the range to represent the difference between the left and right edge of the image, and some time before that a double does not have the range to represent the difference between two pixels. I hit variations on this problem a few times while working on Fractal eXtreme.
SuperFractalThing can go beyond 10^308. It does this by scaling the A, B and C coefficients. I haven't really tested this very much, I have just zoomed in on one point to 10^400. If the result from equation (2) is to small to be stored in double precision floating point then SuperFractalThing will fail, but I think it would need an extremely chaotic image for that to happen. |
|
|
|
« Last Edit: May 12, 2013, 07:29:41 PM by mrflay »
|
Logged
|
|
|
|
|
cbuchner1
|
|
« Reply #24 on: May 13, 2013, 05:17:59 PM » |
|
Does the perturbation theory maths also apply to 3D rendering of Mandelbulb, Mandelbox and other hybrids? If so, it could greatly speed up the non-DE based raytracing methods.
|
|
|
|
|
Logged
|
|
|
|
|
cKleinhuis
|
|
« Reply #25 on: May 13, 2013, 05:29:05 PM » |
|
i think it would work ... but it has to be carefully developped, mrflay has done the work for the mandelbrot equation, other formulas need careful development of such ... but in general what the paper states is that pertubation theory can provide faster solutions for harder problems ... but this would not be easy to achieve .... you can *try* to rego the steps with the 3d version and triplex mathes, but as long as i do not have implemented the method by myself, and fully understand how he developed the formulas i wont touch any higher dimension or other formulas with such  @mrflay is the sourcecode available for this program? i am really interested in a very deep zoom mandelbrot explorer using the gpu, this would be reeeeeeeeeeeeeeaally awesome for now |
|
|
|
|
Logged
|
---
divide and conquer - iterate and rule - chaos is No random!
|
|
|
|
Kalles Fraktaler
|
|
« Reply #26 on: May 14, 2013, 08:29:27 AM » |
|
This sound really amazing, as soon as I get a little time I can't wait to lay my hands on this. I searched a little on google for "pertubation superfractalthing" and found that there is what it seems a desktop application however only available on Mac. Have any mac users tested it? If it is possible to render Mandelbrot fractals in Java so many times faster than Fractal extreme, one can only guess the possibilities with a program written in optimized C++ and assembler...  This MAC application seems to be a couple of years old, so this does not seem to be any news at all. How did we enthusiasts missed it for so long...? |
|
|
|
|
Logged
|
|
|
|
|
Dinkydau
|
|
« Reply #27 on: May 14, 2013, 01:18:38 PM » |
|
Yes, I have been thinking of installing mac OS on my computer just for this application. I don't think it would change my everday life actually; photoshop and after effects are available for mac, browsers are available for mac, and I assume there must be some MSN application for mac as well.
|
|
|
|
|
Logged
|
|
|
|
|
mrflay
|
|
« Reply #28 on: May 15, 2013, 12:09:19 AM » |
|
@mrflay is the sourcecode available for this program? i am really interested in a very deep zoom mandelbrot explorer using the gpu, this would be reeeeeeeeeeeeeeaally awesome for now I'm planning on having a look at releasing the java app source as open source at the weekend. However I might get distracted by making a single precision version of SFT to test the feasibility of the gpu idea. |
|
|
|
|
Logged
|
|
|
|
|
cbuchner1
|
|
« Reply #29 on: May 15, 2013, 01:50:30 AM » |
|
I'm planning on having a look at releasing the java app source as open source at the weekend. However I might get distracted by making a single precision version of SFT to test the feasibility of the gpu idea.
even with single precision not fully working, there is the option to use the DSMATH library to combine two single precision floats into something that is more precise than a float, but somewhat less precise than a double. for a CUDA implementation https://devtalk.nvidia.com/default/topic/394729/emulated-double-precision-double-single-routine-header/I am certain an OpenGL (GLSL) and OpenCL variant will be possible as well. The speed would be about 4 times slower than using float (yet still much faster than one's CPU could do double precision maths using SSE2 or AVX), and will run on older GPU hardware that doesn't have native double precision support. Christian |
|
|
|
« Last Edit: May 15, 2013, 12:13:44 PM by cbuchner1 »
|
Logged
|
|
|
|
|










